OR、HR、RR:三个经常把人弄晕的概念
在医学统计学中,有三个关于比值的概念,分别为相对危险度(relative risk,RR,也称 risk ratio)、风险比(hazard ratio,HR)和优势比(odds ratio,OR)。很多同行一看见这三个概念就感觉恶心反胃、头皮发麻、窦性心动过速,大有雾里看花,水中望月的感觉。在此,笔者拟谈谈如何正确理解这三个概念的区别和联系。
我们以病因学研究为例,先谈谈 OR 与 RR 的区别,因为这两个指标均可以从四格表中衍生出来。我们先来看看两个关于吸烟与肺癌的例子:
例1:为明确吸烟与肺癌的关系,某研究者在 1985 年随机调查了某社区的 10000 名居民,并每年对其进行随访,以观察其肺癌的发生状况在刚刚进行调查的时候,他就发现这 10000 个居民中有 3000 人吸烟,7000 人不吸烟。在本例中,我们假定吸烟和不吸烟居民之间不存在交叉污染,即吸烟的 3000 人永远不会戒烟,而不吸烟的 7000人 也永远不会吸烟。且这 10000 个人不会失访。随访 30 年后,吸烟的 3000 人中有 300 人得了肺癌。相比之下,不吸烟的 7000 人中仅有 70 人患肺癌。如表1所示:
表1 吸烟与肺癌的关系
| 患肺癌 | 无肺癌 | |
| 吸烟 | 300(a) | 2700(b) |
| 不吸烟 | 70(c) | 6930(d) |
RR 的定义是:暴露组发病率或死亡率与非暴露组发病率或死亡率之比。
在本案例中,吸烟人群 30 年内发生肺癌的比例为 0.10(300/3000),而不吸烟人群发生肺癌的比例为 0.01(70/7000)。因此,与非吸烟人群相比,吸烟人群发生肺癌的相对危险度(RR)为:0.10/0.01=10,即可以认为吸烟人群 30 年内发生肺癌的风险是非吸烟人群的 10 倍。实际上,不难看出,RR 在四格表中的计算公式就是:RR=(a/(a+b))/(c/(c+d))。
例2:某医生怀疑吸烟与肺癌有关,因为他发现自己经手的很多肺癌患者都有吸烟史。于是他在 2015 年找了 100 名肺癌患者和 100 名健康对照,回溯了他们的过去 30 年的吸烟史,结果发现:100 名肺癌患者中 90 名患者有吸烟史,100 名健康个体中仅有20人有吸烟史。如表2所示:
表2 吸烟与肺癌的关系
| 吸烟 | 不吸烟 | |
| 肺癌 | 90(a) | 10(b) |
| 健康个体 | 20(c) | 80(d) |
OR 的定义是:病例组中暴露人数与非暴露人数的比值除以对照组中暴露人数与非暴露人数的比值。这里的“暴露”其实就是指“吸烟”。在本案例中,肺癌组暴露人数与非暴露人数的比值为 9(90/10),而在健康个体中,暴露人数与非暴露人数的比值为 0.25(20/80)。因此,OR 为:9/0.25=36。由此我们也不难看出,OR 在四格表中的计算公式为:OR=ad/bc。
部分读者看到这里可能觉得有点糊,按理说 RR 的临床解释最为清晰,说得通俗点就是:吸烟个体发生肺癌的风险是非吸烟个体的多少倍。相比之下,OR 的临床解释则要复杂得多。为何表1用 RR 来描述吸烟与肺癌的关联强度,表2则要用 OR 来描述呢?按理说,只要是四格表,都可以计算 RR,为什么流行病学家还搞个 OR 在这里呢?的确,所有的四格表都可以计算 RR,比如我们将表2调整为如下格式(表3),当然也可以计算 RR:
表3 吸烟与肺癌的关系
| 患肺癌 | 无肺癌 | |
| 吸烟 | 90 | 20 |
| 不吸烟 | 10 | 80 |
RR 的计算过程为:吸烟人群中有 110 名个体吸烟,90 例发生了肺癌,肺癌发生风险约为 0.82(90/110);不吸烟的 90 名个体中,仅有 10 人发生肺癌,因此肺癌的发生风险是 0.11(10/90)。因此与不吸烟的个体相比,吸烟个体发生肺癌的风险约为 7.45 倍(0.82/0.11)。
然而,表2绝对不能转化成表3的格式,这是有研究的性质决定的,表1的数据来源于队列研究,表2的数据来源于病例对照研究。
如前述章节(有病例和对照的研究就是病例-对照研究?、实验组和对照组的样本量一定要“均衡”才行?)所述,队列研究和病例对照研究有很大的区别,这些区别概括起来就是:队列研究是前瞻性研究,是由因索果的研究;病例对照研究是回顾性研究,是由果索因的研究。前瞻性研究最大的优势在于:“真实世界”尚未发生,因为研究者可以详尽地描述“真实世界”,体现在:抽取的 10000 名研究对象实际上就是来自于“真实世界”的,因为研究者是从普通人群中随机抽取研究对象的;研究对象中吸烟个体的比例为 0.30,也是反映了真实情况,即现实生活中,吸烟个体的比例就是 0.30;随访 30 年后,总共有 370 人发生了肺癌(患病率为 3.7%),这一患病率也是来源于真实世界的结论。由于其得出的 RR 值是来自于真实世界的,因此具有“外推性”,或者说“泛化性”,可以直接地告诉人们吸烟的患者发生肺癌的风险是不吸烟患者的多少倍。
相比之下,病例对照研究就没有那么简单了,因为病例对照研究是先知道结局,再去回溯原因,此时,“真实世界”已经一去不复返了,哪里还能完整地回溯回来?研究者募集了 100 名肺癌患者和 100 名健康个体,实际上就是假定了肺癌的患病率为 0.50,这一数字显然不是来自于真实世界。在真实世界中,过去 30 年肺癌的发生了是多少呢?没有人会知道这个精确的数字。因此,如果强行用 RR 来展示病例对照研究结果的话,没有多大的临床价值,因为这个 RR 不是来自真实世界的,不具备“外推性”。流行病学家不得已,才在这里提出了一个 OR 的概念,用于反映暴露因素与结局事件的关联强度。如前所述,OR 这个指标在四格表中的计算公式:OR=ad/bc,实际上也可以表示为(a/b)/(c/d)。理论上讲,不管实验组样本为多少例,a/b 是不变的(当然可能会有一些小的波动,但属于抽样误差);同理,不管对照组样本量如何变化,c/d 的比例也是固定的。因此,OR 最大的优势的是不受实验组和对照组比例(或者说患病率)的影响。这也就是为什么在病例对照研究中人们喜欢用 OR 来表示暴露因素与结局事件关联强度的原因所在。
我们不妨来做一个根本就不存在的假设。我们假设表1中的队列研究的资料是完全存在的,只是没有发表。后来,有人用病例对照的研究思路来阐述吸烟与肺癌的关系。从表1我们得知,过去三十年,这个社区总共发生了 370 例肺癌,其中 300 个肺癌患者具有吸烟史,70 个不具有吸烟史。因此如果从中抽取 100 例肺癌的话,理论上说就应该是 81 个肺癌患者有吸烟史,19 个肺癌患者没有吸烟史。健康个体一共有 9630 个,其中 2700 个吸烟,6930 个不吸烟,如果从这 9630 个健康个体中抽取 100 人的话,就应该有 28 个人吸烟,72 个人不吸烟。于是可以得出下表(表4):
表4 吸烟与肺癌的关系
| 患肺癌 | 无肺癌 | |
| 吸烟 | 81 | 28 |
| 不吸烟 | 19 | 72 |
根据表4的内容不难算出,与非吸烟个体相比,吸烟患者发生肺癌的 RR 是 3.56(计算过程略),该 RR 值与表1的 RR 值(10)相距甚远。假定我们抽取的健康个体不是 100 人,而是 200 人,则可以算出 RR 为 5.07(计算过程略)。由此可知,RR 在很大程度上受患病率的影响,病例对照研究之所以不能计算 RR,就是因为其患病率是假设的,就算勉强计算出 RR 也不具备外推性,没啥意思。
OR 的临床解释是什么呢?笔者一般不喜欢去解释,因为解释的文字读起来也很繁琐,且个人认为临床价值不高。对于我们而言,只需要记住 OR 大于 1 表示暴露因素是危险因素,OR 小于 1 则表示暴露因素是保护因素即可。
前述 OR 和 RR 都来源于四格表,即仅仅考虑了一个暴露因素(吸烟)与结局事件(肺癌)的关系。而在现实中,疾病的发生往往不是单一因素作用的结果。比如:假定吸烟的人都不太喜欢吃水果,而水果摄入过少也可以导致肺癌。因此很有可能出现一种极端的情况,其实吸烟与肺癌无关,我们之所以在队列研究或病例对照研究中观察到了吸烟与肺癌的关系,完全是“吃水果”作怪。此时,我们将“吃水果”称为“混杂因素”,即表示他们可能会干扰暴露因素与结局变量之间的关系。为了排除混杂因素的干扰,需要在统计学上做一些校正,比较常用的方法就是 Cox 风险比例模型和 logistic 回归模型。一说到 Cox 风险比例模型和 logistic 回归模型,估计很多读者的脑海里马上闪现两个概念,HR 和 OR。没错,这里的 OR 和四格表里面的 OR 其实就是一个意思,只是二者的计算方法不同。来自于 logistic 回归的 OR 可以校正很多混杂因素,因此是一个多因素校正的 OR,而来自于四格表的 OR 只考虑了单一因素,因此可以简单理解为单因素分析的 OR。在撰写论文的过程中,一般认为多因素校正的 OR 更可靠。实际上,如果把四格表的数据用单因素的 logistic 回归方程计算,得到的 OR 是一样的,有兴趣的读者可以自己算。
Cox 模型与 logistic 回归有很多相似之处,都可以用于校正混杂因素。根据 Cox 模型可以计算出 HR 值,HR 值的解释与 RR 几乎一致,即表示暴露组患病的概率为非暴露组的多少倍。但是与 logistic 回归不同的是,Cox 模型除了可以校正混杂因素外,还考虑了结局事件发生的时间。因此,HR 不能简单等同于 RR,只能说 HR 是考虑了时间因素的 RR。说得这里,估计部分读者有点糊,啥叫“考虑了时间因素的 RR”?我们不妨来做这样一个假设:在表1中(队列研究)中,RR 为 10,我们可以理解为:与不吸烟人群相比,吸烟人群在 30 年内患肺癌的风险是不吸烟人群的10倍。注意“30 年内患肺癌的风险”,这是一个很含糊的说法:有人可能在随访开始第二年就发生肺癌,有人可能到随访快结束时(第三十年)才发生肺癌。如果构建四格表,这两个肺癌是同等看待的,但实际上,这两种肺癌的“社会危害性”显然是不能相提并论的!毕竟后者很有可能会多活二十多年。因此,我们在考虑结局事件是否发生的同时,往往还要考虑结局事件发生的时间!这就是 HR 存在的价值!
总结一下本文,以研究疾病发生机制的研究为例来谈谈 RR,OR 和 HR 的区别,实际上,研究疾病预后的研究也可以类推。
RR:主要用于队列研究,可以从四格表衍生出来,表示暴露患者发生疾病的风险是非暴露患者的多少倍。
OR:主要用于病例对照研究和横断面研究,可以从四格表中衍生出来,也可以由logistic回归计算得来,表示病例组中暴露人数与非暴露人数的比值除以对照组中暴露人数与非暴露人数的比值。
HR:主要用于队列研究,主要由 Cox 风险比例模型衍生出来,是考虑了时间因素的 RR。
OR(比值比)和RR(相对危险度)的的区别与联系
最近,有小伙伴咨询小编,病例对照研究是不是只能计算OR,而队列研究就是计算RR?虽然在平时文献阅读中,我们经常会看见OR和RR值,但是到了自己统计分析时,可能会出现无法准确运用的情况。今天,我带大家再一次回顾OR和RR这两个的“老朋友”。
要想正确理解OR和RR,我们需要从概念入手。RR(相对危险度)是指暴露组的累积发病率(或死亡率)与对照组的累积发病率(或死亡率)之比。由于传统的队列研究能直接计算发病率(或死亡率),所以可以用RR来回答暴露组的发病风险是非暴露组的多少倍。当然,有时我们还需要考虑队列中的发病率是否能代表研究目标人群的发病率,因为这将影响用RR来反映暴露与结局之间的关联强度。
病例对照研究是将已经确诊患有某种特定疾病的一组病人作为病例组,以不患该病但具有可比性的一组个体作为对照组,然后进行收集和比较两组研究对象各种可能的危险暴露因素。从试验设计思路来看,我们发现传统的病例对照研究无法计算发病率,所以不能计算RR,只能用OR来反映关联度。OR(比值比)指病例组中暴露与非暴露的比值和对照组中的比值的比,当该疾病率较低时,OR是RR的近似值。
除了能否计算发病率外,我们还需要思考对照组人群的选择,因为这将影响OR与RR之间的关系。
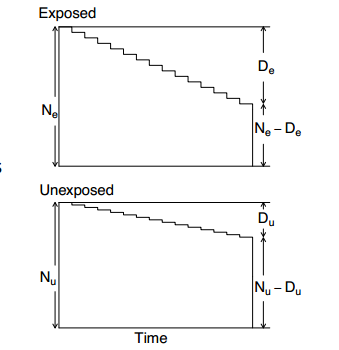
例如上图图例所示,我们将病例对照嵌入一个队列中,Ne和Nu表示队列开始时的暴露人群与非暴露人群,De为暴露人群中的患病者,而Du表示非暴露人群中的患病者,如果我们以随访结束时各组的未患病者作为对照组,此时,表示暴露组的患者比值与对照组的患者比值之比。当该疾病率较低时,Ne-De≈Ne,Nu-Du≈Nu,OR是RR的近似值。但是,如果我们以队列开始时的人群作为对照组时,即Ne为暴露组的对照人群,Nu为非暴露组的对照人群,此时,表示暴露组的累积发病率与对照组的累积发病率之比,所以OR 等于RR,无需疾病率较低的前提假设。因此,选择队列开始时的总人群或随访结束时未患病人群作为对照组时,OR与RR的关系是不一样的。
1. Odds
Odds 的意思为机率、可能性,是指某事件发生的可能性(概率)与不发生的可能性(概率)之比。
2. Odds rate(OR)
Odds ratio 的意思为风险比,在有些参考资料上也叫优势比、比值比。其计算公式为患病组与健康组两个odds之比。
OR常用于流行病学中病例-对照研究资料,表示病例组和对照组的暴露比例与非暴露比例之比。
当odds1>odds2时,OR>1,说明疾病的危险度因暴露而增加,暴露与疾病之间为“正”关联。
3. 相对危险度(RR)
相对危险度(relative risk)是流行病学前瞻性研究的常用指标,其本质为率比(rate ratio)或危险比(risk ratio),即暴露组与非暴露组发病率之比,或发病的概率之比。RR的含义可表示为暴露组的疾病危险性为非暴露组的多少倍。
由于病例-对照研究不能计算发病率,所以病例-对照研究中只能计算OR。当人群中疾病的发病率或者患病率很小时,OR近似等于RR,可用OR值代替RR。当发病率<10%时,RR与OR很接近。当发病率增大时,两者的差别增大。当OR>1时,OR高估了RR,当OR<1时,OR低估了RR。